
Its well known that Lake Cahuilla near La Quinta, CA gets Peninsular bighorn sheep. Here’s one of the rams that ended up posing for me back in 2024


Its well known that Lake Cahuilla near La Quinta, CA gets Peninsular bighorn sheep. Here’s one of the rams that ended up posing for me back in 2024
Hey I just made a numbers to words translator. Takes in a number and translates it to an English integer. Currently only does integers but it does do a range between +/- 999 trillion. Hopefully more to come soon.
You can view it here
… to keep track of magic the gathering games.
Check it out here!
Code I used for echoing out the WordPress enqueued scripts and styles into the JS console (here).
So I recently noticed that when developing child themes some of my CSS was being overwritten by the parent theme. This makes sense because according to WordPress’s developer resources: “the child theme is loaded before the parent theme“. Although that may work in many cases, this wasn’t going to cut it for mine.
I wrote a custom function to enqueue first the parent theme THEN the child theme so that the CSS from the child theme would be read latest and overwrite some of the rules of the parent. Done! Great! Wow! … Not quite…
This lead to a problem of a duplicate child stylesheet being loaded, which in most circumstances wouldn’t cause too much of an issue but in this case it caused errors when performing minor updates. The WordPress generator was stuck enqueuing an older version of my stylesheet along with the update. Needless these two running in congruence caused several issues.
I used some code from Lakewood echo out the scripts and styles enqueued by WordPress so I could find the duplicate script handle and dequeue it. Simple enough! I slapped it in there but unfortunately my duplicate problem stylesheet persisted.
Not to worry. Doing some digging I found that with messing with the priority of the enqueue/dequeue I was able to successfully remove the duplicate. I had to dequeue the duplicate after it was enqueued but before my custom one had enqueued. Anyways thanks for reading.
Function to echo out enqueued scripts and styles.
/**
* Print enqueued style/script handles
* https://lakewood.media/list-enqueued-scripts-handle/
* Modified by Chris Fust for a more JS friendly
* readabily thing.
*/
function lakewood_print_scripts_styles() {
if( !is_admin() && is_user_logged_in() && current_user_can( 'manage_options' )) {
// push scripts and styles to arrays
// so that they appear in the JSON
// in the order they would enqueue
// with wp_enqueue_*()
// local vars
$scripts = [];
$styles = [];
// Print Scripts
global $wp_scripts;
foreach( $wp_scripts->queue as $handle ) :
$scripts[] = array( $handle => $wp_scripts->registered[$handle]->src );
endforeach;
// Print Styles
global $wp_styles;
foreach( $wp_styles->queue as $handle ) :
$styles[] = array( $handle => $wp_styles->registered[$handle]->src );
endforeach;
// echo out scripts and styles
// as separate objects
echo '<script>';
echo 'console.log({ "scripts" : ' . json_encode( $scripts ) . '});';
echo 'console.log({ "styles" : ' . json_encode( $styles ) . '});';
echo '</script>';
}
}
// This is primarily used for debugging so
// I'm going to skip adding this function to the queue
// add_action( 'wp_print_scripts', 'lakewood_print_scripts_styles', 101 );

Hello world! For my research on scavenging guilds in the Australian Alps, I tallied nearly 30,000 insects. To do so, I made a quick web-based tool that I could quickly tally what I found. Its easy to use including features to copy the tally in a table format to paste into MS Excel.
I know this is a tool taylored specifically for my project, but I think its functionality can be applied for others out there.

Australia lacks a robust vertebrate scavenger guild which allows insects to outcompete them at carrion. Insects are the primary decomposers in the Australian Alps
Hello world!
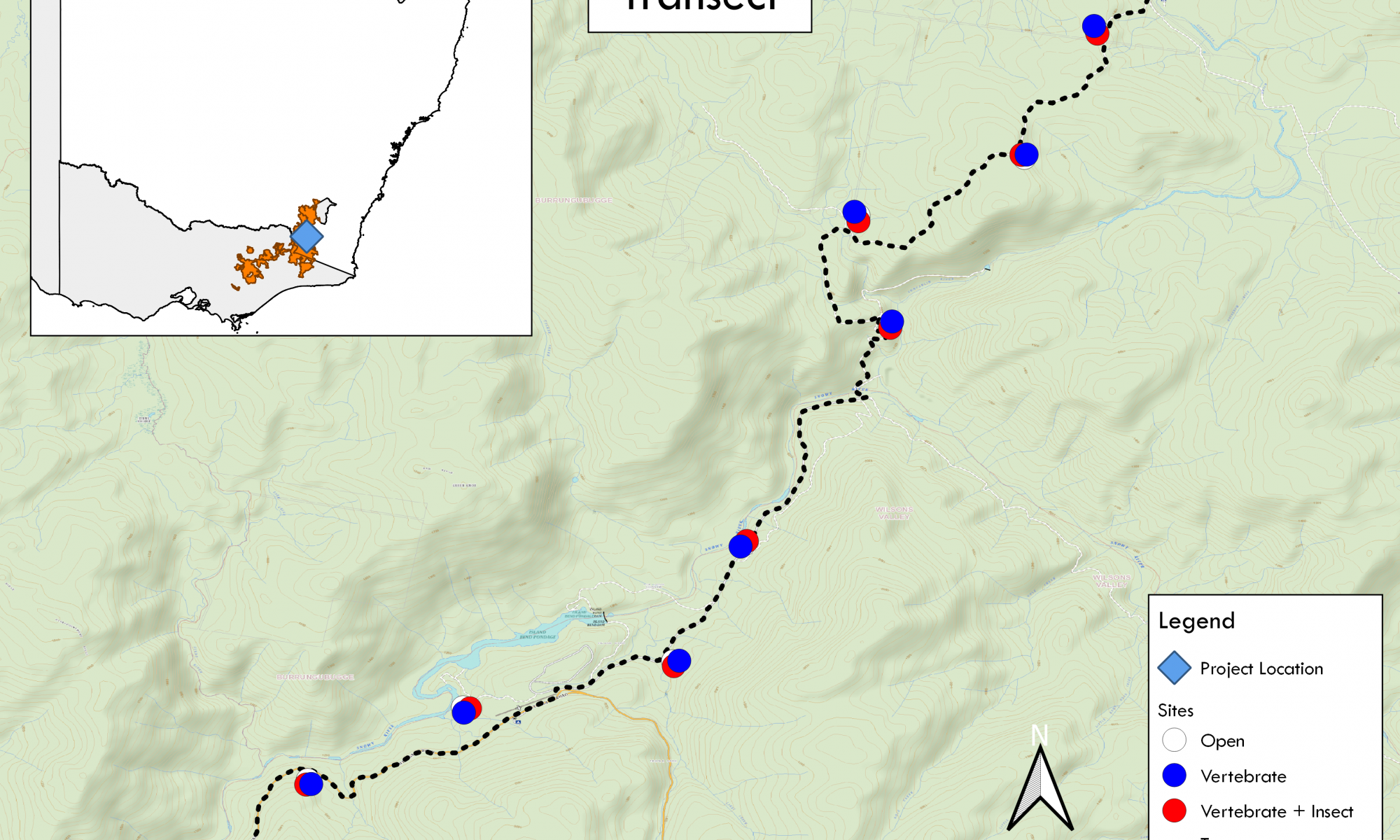
I’d like to share some maps I’ve made of my master’s project. I’ve conducted an ecological project looking at scavenging dynamics in the Australian Alps, specifically in Kosciuszko National Park in New South Wales. The maps show the Australian Alps (the highest region in mainland Australia) and my autumn replicate transect. The transect runs along Island Bend Fire Trail and Guthega road. Each site is roughly 1km distance from each other with treatments approximately 50m from one another.
Each site consists of three treatments 1) Open / No Exclusion, 2) Vertebrate Exclusion, and 3) Vertebrate + Insect Exclusion.
These maps were produced with QGIS version 3.2+.

OK so here’s an update to the permutation pyramid I made.
I had to make a list of different permutations of models but it became hard to keep track of all the different variables and their combinations. Hence, the permutation pyramid. The goal is to make a list of vector combinations and permutations. I found this super useful when generating formulas for AICc/Model selection.
Enjoy!
The function has a few options:
pyramid <- function( vec, order.matters = FALSE, req, interact ){
# pyramid of variable combinations
# this doesn't include different
# arrangements
vrz <- lapply(
1:length( vec ),
function( x ){
combn( vec, x ) %>% as.data.frame()
}
) %>% purrr::flatten() %>% unname()
# If there are interactions
if( !missing( interact ) ){
# possible interaction combos
intx <- seq( from = 1, to = length( interact ), by = 1 ) %>% knp.perm.pyramid()
# extra interactions
vrz.int <- list()
# look through vars
for( v in vrz ){
# make a list of interactions
# and add them to the list
vrz.int <- append(
vrz.int,
lapply( intx, function( ints ){
# count number of matches to compare
# and filter out unaltered var lists
mt <- 0
# for each interaction
# check if its in the array
# then add it if it is
for ( int in ints ) {
if(
length( intersect( v, interact[[ int ]] ) ) == length( interact[[ int ]] ) &
length( interact[[ int ]] ) > 1
){
v <- c( v, paste0( interact[[ int ]], collapse = ":" ) )
mt <- mt + 1
}
}
# if the number of matches equals
# the number of interactions then
# return the altered array
if( mt == length(ints) ){
return( v )
}
return( NULL )
}) %>% plyr::compact()
)
}
# append interactions
vrz <- append( vrz, vrz.int )
}
# order matters so lets rearrange
if( order.matters ){
vrz <- lapply( vrz, function( x ){
combinat::permn( x )
}) %>% purrr::flatten()
}
# if there's any required variables in each combination
if( !missing( req ) ){
vrz <- lapply(vrz, function( x ){
if( length( intersect( x, req ) ) == length( req ) ){
return( x )
}
return( NULL )
}) %>% plyr::compact()
}
# return list of character
# permutations
return( vrz )
}
Plain vanilla use
> a <- c( "A", "B", "C" )
> pyramid( a )
[[1]]
[1] "A"
[[2]]
[1] "B"
[[3]]
[1] "C"
[[4]]
[1] "A" "B"
[[5]]
[1] "A" "C"
[[6]]
[1] "B" "C"
[[7]]
[1] "A" "B" "C"
If the order of the elements matters
> a <- c( "A", "B", "C" )
> pyramid( a, order.matters = TRUE )
[[1]]
[1] "A"
[[2]]
[1] "B"
[[3]]
[1] "C"
[[4]]
[1] "A" "B"
[[5]]
[1] "B" "A"
[[6]]
[1] "A" "C"
[[7]]
[1] "C" "A"
[[8]]
[1] "B" "C"
[[9]]
[1] "C" "B"
[[10]]
[1] "A" "B" "C"
[[11]]
[1] "A" "C" "B"
[[12]]
[1] "C" "A" "B"
[[13]]
[1] "C" "B" "A"
[[14]]
[1] "B" "C" "A"
[[15]]
[1] "B" "A" "C"
Require variables
> a <- c( "A", "B", "C", "D", "E" )
> b <- c( "B", "D" )
> pyramid( a, req = b )
[[1]]
[1] "B" "D"
[[2]]
[1] "A" "B" "D"
[[3]]
[1] "B" "C" "D"
[[4]]
[1] "B" "D" "E"
[[5]]
[1] "A" "B" "C" "D"
[[6]]
[1] "A" "B" "D" "E"
[[7]]
[1] "B" "C" "D" "E"
[[8]]
[1] "A" "B" "C" "D" "E"
Include interactions
> a <- c( "A", "B", "C")
> b <- list( c( "A", "B" ), c( "A", "B", "C" ) )
> pyramid( a, interact = b )
[[1]]
[1] "A"
[[2]]
[1] "B"
[[3]]
[1] "C"
[[4]]
[1] "A" "B"
[[5]]
[1] "A" "C"
[[6]]
[1] "B" "C"
[[7]]
[1] "A" "B" "C"
[[8]]
[1] "A" "B" "A:B"
[[9]]
[1] "A" "B" "C" "A:B"
[[10]]
[1] "A" "B" "C" "A:B:C"
[[11]]
[1] "A" "B" "C" "A:B" "A:B:C"
So I had to make a combination of different values based on elements in a vector. With a few tweaks and what not I made a little function to find all the combinations and permutations of a given vector. Enjoy
The function:
# creat a list of combinations and
# permutations of elements from
# a single vector. This requires
# a few libraries:
# library( dplyr )
# library( purrr )
# library( combinat )
# "order.matters" is means that
# for every combination of elements
# find every order they can be
# arranged.
permutation.pyramid <- function( v, order.matters = TRUE ){
# get the unique combinations of elements
# and flatten them into a one dimensional list
out <- 1:length(v) %>%
lapply(function( x ){
combn( v, x ) %>% as.data.frame()
}) %>%
purrr::flatten() %>%
unname()
# if order.matters then find all the
# arrangements of each combination
if( order.matters ){
out <- out %>%
lapply(function( x ){
combinat::permn( x )
}) %>%
purrr::flatten()
}
# return list of permutations
return( out )
}
Use and examples.
Find all combinations and permutations of a given vector
> test <- c("A","B","C")
> permutation.pyramid( test )
[[1]]
[1] "A"
[[2]]
[1] "B"
[[3]]
[1] "C"
[[4]]
[1] "A" "B"
[[5]]
[1] "B" "A"
[[6]]
[1] "A" "C"
[[7]]
[1] "C" "A"
[[8]]
[1] "B" "C"
[[9]]
[1] "C" "B"
[[10]]
[1] "A" "B" "C"
[[11]]
[1] "A" "C" "B"
[[12]]
[1] "C" "A" "B"
[[13]]
[1] "C" "B" "A"
[[14]]
[1] "B" "C" "A"
[[15]]
[1] "B" "A" "C"
Find all combinations of vector
> test <- c("A","B","C")
> permutation.pyramid( test, order.matters = FALSE )
[[1]]
[1] "A"
[[2]]
[1] "B"
[[3]]
[1] "C"
[[4]]
[1] "A" "B"
[[5]]
[1] "A" "C"
[[6]]
[1] "B" "C"
[[7]]
[1] "A" "B" "C"
Anyways I hope that’ll be useful for someone!
A small little function written in R to get the 95% confidence intervals and some quick stats of a vector. I found this useful in error reporting in some stats. I got the concept from this tutorial.
This does require the dplyr library
Function
library( dplyr )
ci <- function( x ){
cnf <- dplyr::tibble(
mean = mean( x, na.rm = TRUE),
st.dev = sd( x, na.rm = TRUE),
n = length( x ),
error = qnorm( 0.975 ) * st.dev / sqrt( n ),
ci05 = mean - error,
ci95 = mean + error
)
cat( cnf$mean, "(", cnf$ci05, "-", cnf$ci95, ")\n" )
return( cnf )
}
Use
> x <- sample(10)
> ci(x)
5.5 ( 3.623477 - 7.376523 )
# A tibble: 1 x 6
mean st.dev n error ci05 ci95
<dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 5.5 3.03 10 1.88 3.62 7.38